Pair Decomposition (Packing) Ideas¶
All scores should be pair-decomposable. In combination with the gridded ridged body kinematic model, this allows any system with more than two rigid bodies to be optimized by precomputing pair-energy tables. By analogy to the packer, each rigid body is like a “residue” and each sampled position of a rigid body is like a “rotamer.”
Pair decomposition of score calculations is a key concept for combinatorial optimization of protein structure. It is the basis for the Rosetta packer, and other protein design methods such as DEE/A*. The core concept is that no matter how many degrees of freedom there are in a system of independently changing bodies, the energetics of the system can be captured (if the energy function is pair-decomposable) entirely by the pair interactions only. Of course these are coupled, but it does mean that score calculations can be done once to produce one and two body score tables. Then optimization can be carried out entirely with lookups into the precomputed score tables.
This notion is highly complimentary with hierarchical search. At each stage of the search hierarchy, a pair-decomposition and optimization procedure is applied to the states listed for evaluation in that phase of the hierarchy.
The pair-decomposition of energies, which is the basis for “packer” type algorithms, should be universally applicable for faster energy calculations in all systems with more than two bodies (or two + symmetry), provided sampling is all on a predefined grid. So I’m thinking this should be build into some kind of universal energy caching data structure. (It would even be of use in folding-type kinematics, you could al least have your N to N+1 and N to N+2 interactions precomputed and never have to repeat them. And/or do some type of annealing/DEE on the local interactions and see what you get globally… branch and bound won’t be possible, but it may still work well) To do this requires adding a little more facility to the CompositeGrid and kinematics to extract the degrees of freedom that place individual bodies and pairs of bodies, but it should be possible to do it in a general manner. Sorting out the indexing will likely be a headache.
Hierarchical Packing¶
Illustration of hierarchical packing, one cycle.
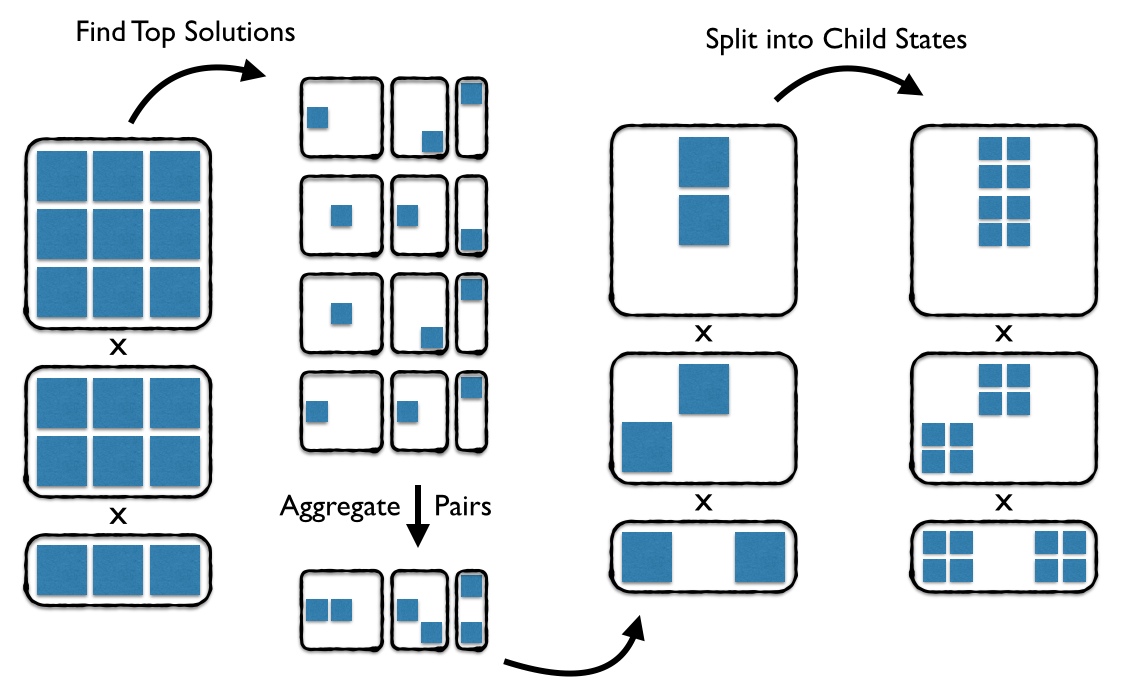
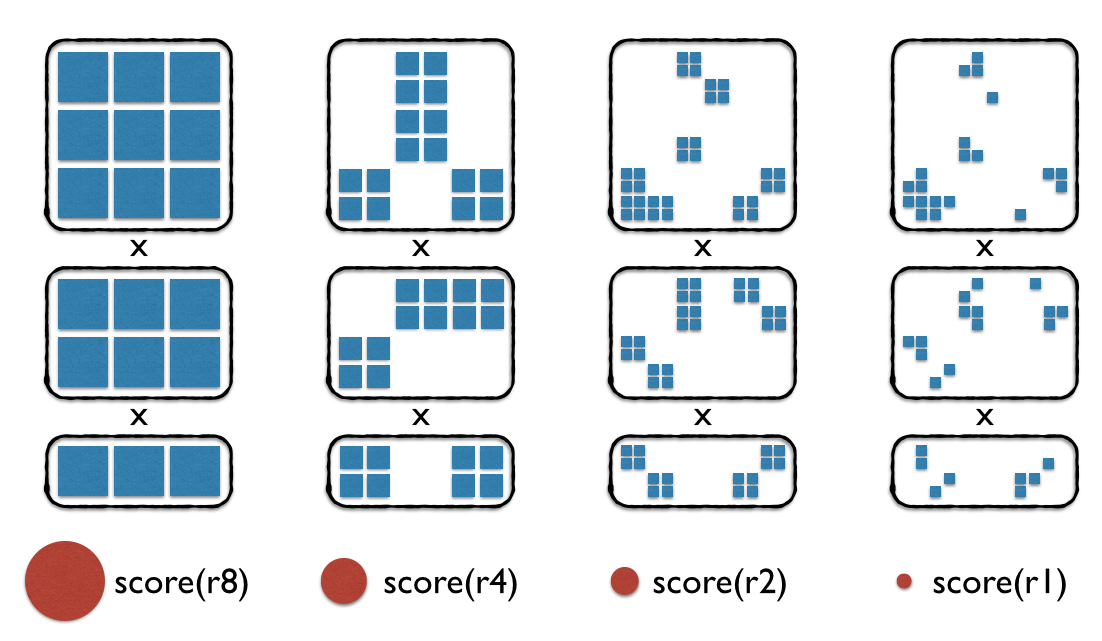
Illustration of considered states over four round of hierarchical packing. Red circles: Covering radius (i.e. radius or convergence, resolution) of the score function used in a given round… must be be matched to the sampling resolution.
Rosetta Analogy¶
In rosetta design, we generally include “extra” rotamers when packing. These extra rotamers are generated by taking the base rotamers and tweaking them a little, say by adding ±1 standard deviation to each chi angle. These extras are all added into the rotamer pool and treated uniformly, ignoring their relationship to the “parent” rotamer. In practice, we generally do exactly this, with 3**Nchi total rotamers, because it improves the designs that come out and the extra work isn’t too much. But what if you want to sample rotamers more finely? One of the extra rotamer modes in rosetta is ±0.5, 1.0 and 1.5 sd, yielding 7**Nchi rotamers per residue. This produces a “rotamer explosion” making the packing problem too big to solve in a reasonable amount of time/memory.
If you wanted to take advantage of these closely-related rotamers to reduce the calculation, you could do something like this:
Pack with no extra rotamers using a very soft score function.
take the top 10,000 solutions produced by the packer and for only the rotamers involved in those top 10,000 solutions, add +-1 SD rotamers.
now repack with this expanded-subset of rotmers with a lightly soft energy function.
Again take the top 10,000 solutions. Make a new rotamer set with only rotamers involved in those solutions, and add in +-0.5 SD rotamers.
now repack with the standard hard energy function.
Hopefully this gives some feeling for how hierarchical packing will work in scheme. I’m not sure how well this would work without carefully “softening” the energy function in Rosetta. In scheme score functions of the appropriate “covering radius” can easily be generated. Probably best with bounding energies.
Scheme Hierarchical Packing Use Case¶
Write me!
Challenges¶
Packing Algorithm¶
We need a “Packer” that can emit a large set of top solutions efficiently. DEE would be nice for optimality, but it may be too slow.
Bollox to DEE and clever algorithms, Monte Carlo with some quenching and a small taboo list seems to work great. Try a billion substitutions, keep the top million things you see, done in 60 seconds.